
Китайский стартап в области искусственного интеллекта Z.ai (ранее Zhipu) сообщил о выпуске большой языковой модели GLM-5.2 с открытыми весами и 753 млрд параметров. Её основное предназначение — написание программного кода и разработка с «длительным горизонтом планирования».

Содержание статьи
- 1 Ryzen и DDR5-6000 на чипах Samsung — G.Skill даёт добро
- 2 Обзор Ryzen 9 9950X3D2: правильный 16-ядерник с 3D-кешем
- 3 Обзор Intel Core Ultra 5 250K Plus, или Как Arrow Lake превратился в «топ за свои деньги»
- 4 Обзор Intel Core Ultra 7 270K Plus — лучший Arrow Lake за полцены
- 5 72 полёта над Марсом: как Ingenuity пережил зиму, сбои и собственную миссию
- 6 Выбираем лучший игровой ноутбук до 100 000 рублей: сравнительное тестирование 7 интересных моделей
Ryzen и DDR5-6000 на чипах Samsung — G.Skill даёт добро

Обзор Ryzen 9 9950X3D2: правильный 16-ядерник с 3D-кешем

Обзор Intel Core Ultra 5 250K Plus, или Как Arrow Lake превратился в «топ за свои деньги»

Обзор Intel Core Ultra 7 270K Plus — лучший Arrow Lake за полцены

72 полёта над Марсом: как Ingenuity пережил зиму, сбои и собственную миссию

Выбираем лучший игровой ноутбук до 100 000 рублей: сравнительное тестирование 7 интересных моделей

Источник изображения: Steve A Johnson / unsplash.com
Поработать с моделью можно через API на ресурсах Z.ai, на платформе Hugging Face; поддерживаются более 20 сторонних сред разработки. Модель предлагает контекстное окно в 1 млн токенов; корпоративные подписки стоят от $12,60 в месяц. Основные веса GLM-5.2 доступны по лицензии MIT — предприятия могут бесплатно скачивать, настраивать и дорабатывать модель по своему усмотрению, запуская её локально или через виртуальные машины, оплачивая только вычислительные ресурсы и электроэнергию.
Источник изображения: z.ai
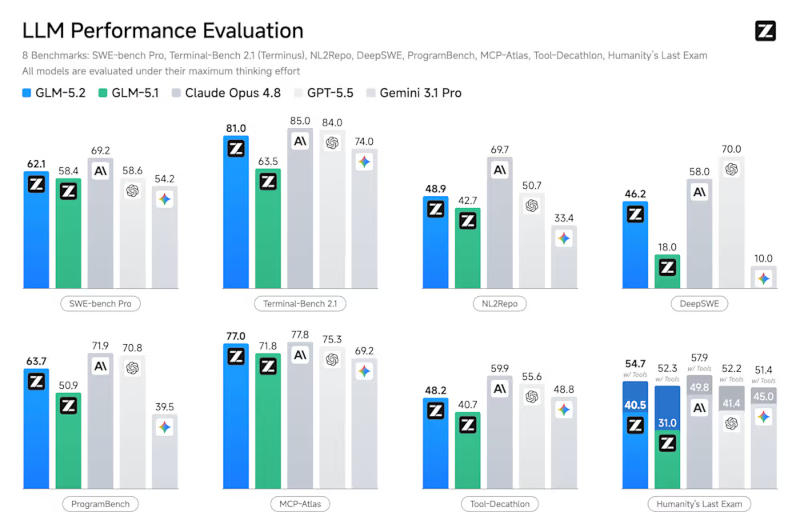
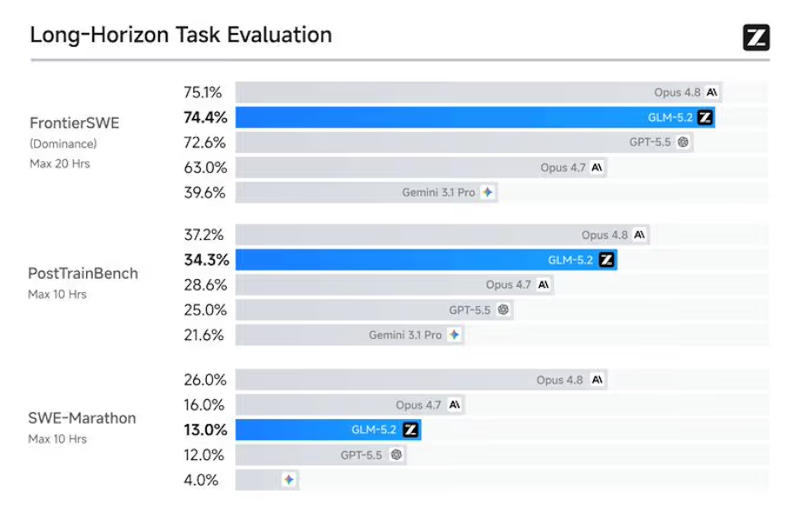
Модель Z.ai GLM-5.2 имеет 753 млрд параметров, и в ней реализована важная архитектурная оптимизация IndexShare — на четыре слоя разрежённого внимания повторно используется один индексатор, что при максимальной длине контекста в 1 млн токенов помогает снизить вычислительную нагрузку в 2,9 раза. Используется также модернизированная схема многотокенного предсказания (MTP), которая при запуске метода спекулятивного декодирования пропускает на 20 % больше токенов при инференсе — это тоже помогает экономить ресурсы.
Источник изображения: z.ai
Модель позволяет выбирать «режимы рассуждений»: «максимальный» помогает расширить границы при решении логических задач, а «высокий» обеспечивает баланс между высокой производительностью и эффективностью при генерации токенов. В первом случае она выдаёт в среднем 85 000 токенов на задачу, а во втором — вдвое меньше. В стандартных отраслевых тестах Z.ai GLM-5.2 превзошла большинство флагманских открытых моделей, а также выступила близко или лучше, чем передовые закрытые модели, в том числе OpenAI GPT-5.5 и Anthropic Claude Opus 4.8.
Для работы с моделью разработчик открыл тариф GLM Coding Plan, ориентированный на подключение средств разработки, а не традиционный интерфейс чат-ботов — поддерживаются такие приложения как Claude Code, OpenClaw, Cline, Kilo Code, Crush и Factory. Тариф Lite ($12,60 в месяц или $151,20 в год, начиная со второго года) предназначен для несложных итераций в небольших репозиториях; Pro ($50,40 в месяц) предлагает впятеро больше вычислительных ресурсов, чем Lite; Max ($112,00 в месяц) предлагает в 20 раз больше ресурсов, чем Lite, и выделенные ресурсы в часы пик. Доступ по API к GLM-5.2 стоит $1,40 за 1 млн входных токенов и $4,40 за 1 млн выходных.


